GenAI is Quietly Revolutionizing Brain-Computer Interfaces
How the fusion of neuroscience and language models is helping us decode thoughts into text
June 6, 2025
There is no shortage of AI excitement, from the latest language model release to the promise of AI agents and autonomous vehicles. It is therefore a rarity that an interesting AI advance would go unnoticed. However, as a neuroscientist turned ML engineer, I keep an eye on the intersection of ML and biology, and a surprising area of research is gaining traction while remaining curiously low-profile.
Namely, LLMs are being adapted to non-invasively decode brain activity, such as what one is thinking, seeing or hearing, into readable text. The popular term is “mind reading” but a more precise and less laden description would be “neural decoding” or “neural guided text generation”. The main approaches involve EEG (using electrodes to measure brain activity from your scalp) and fMRI (using a magnet to measure blood flow changes in your brain over time). The results are increasingly robust.
Almost equally surprising is that these developments are under-acknowledged in the tech community. I hear astonishment that an “AI agent could book your flights” while the prospect of a generative AI system transforming your thoughts into text gets periodic press but otherwise seems largely dormant from discussion.
The papers that got my attention
I highlight two papers below to illustrate the current scene, but I recommend a firsthand read, or if nothing else, dropping them into NotebookLM.
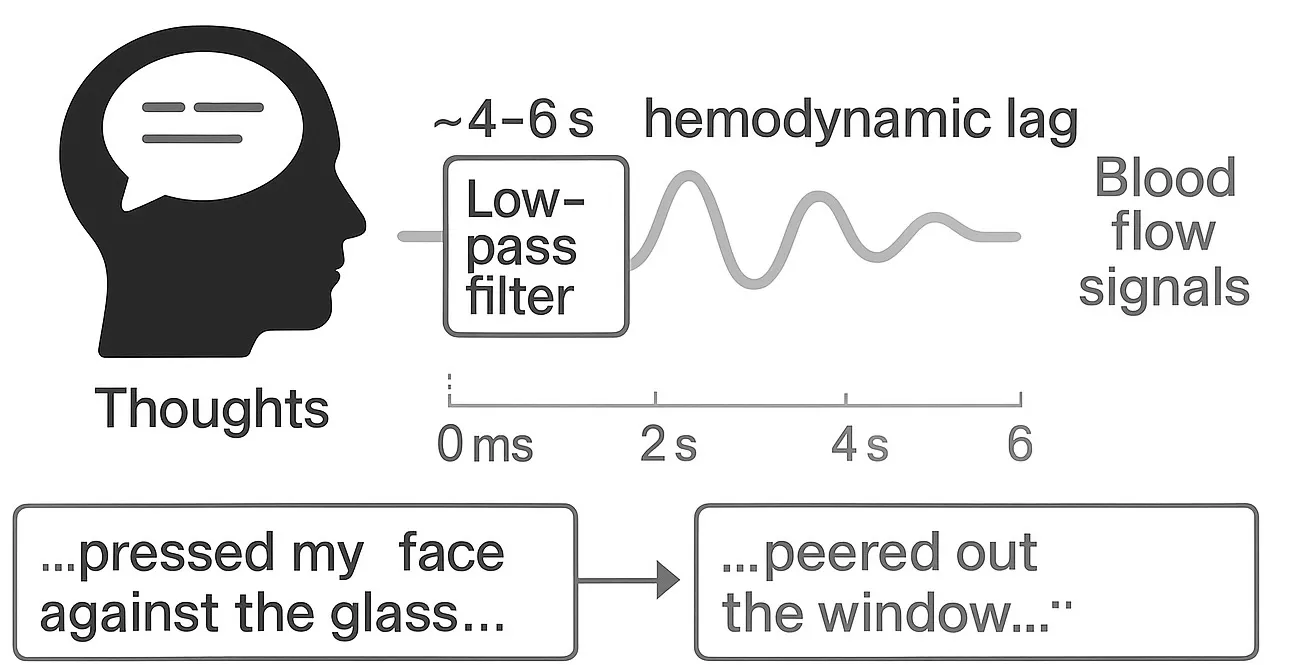
First is a 2023 paper “Semantic reconstruction of continuous language from non-invasive brain recordings” from Tang et al. in Nature Neuroscience. They combine fMRI and GPT to decode language from brain scans using blood flow patterns, which change in response to neural activity, such as when listening to someone talk. To train their model, participants laid in fMRI machines and listened to podcasts while their ML system learned to map brain blood flow patterns to corresponding audio transcripts. The result was quite startling. For example, after model training, when a subject heard:
…i got up from the air mattress and pressed my face against the glass…
their system decoded:
…i just continued to walk up to the window and open the glass i stood on my toes and peered out…
This imprecision may actually stem from a key challenge in this study that arose when aligning sluggish blood-flow changes with fast-moving speech, since each operate at very different speeds. When you hear the word “sunrise,” neurons in your brain fire within milliseconds but the corresponding blood flow signals that fMRIs detect are delayed by about 4-6 seconds. They addressed this mismatch by treating blood flow patterns as a low-pass filter and used a series of ML steps to reconstruct the underlying semantic content, albeit with some information loss. This basically means that they could recover the impression or “gist” of what subjects were thinking but not verbatim thoughts. They evaluated their system across several scenarios, including decoding inner monologues and what subjects saw while watching silent films, which are truly fascinating.
It is worth noting that this type of thought recovery requires voluntary participation. Subjects could intentionally thwart decoding by various means such as silently counting. As malicious use is a clear ethical concern, this finding is encouraging.
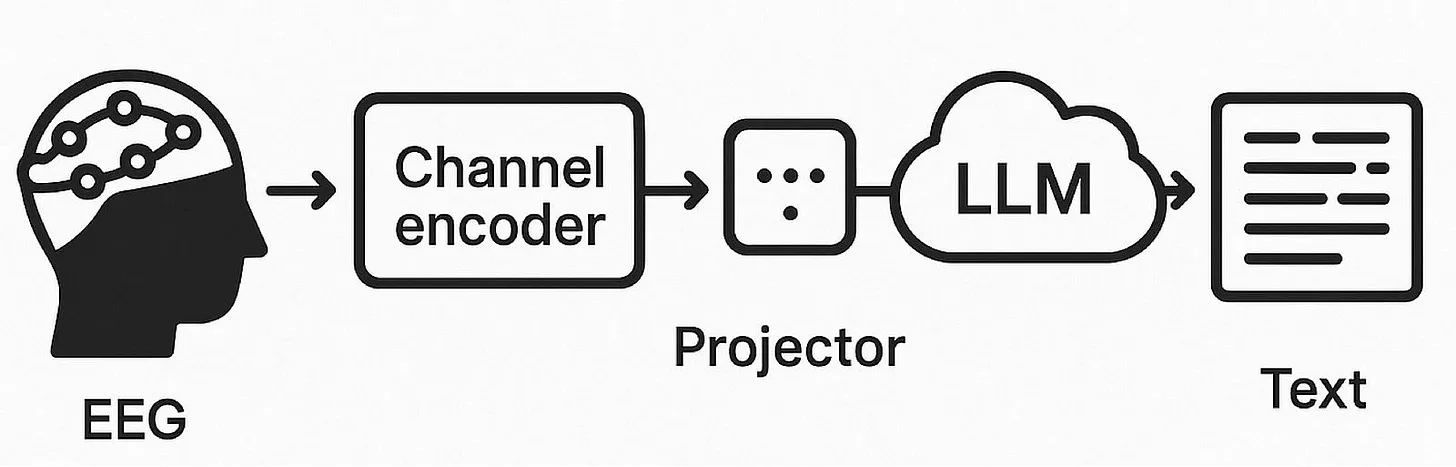
The second paper is from 2025 called “Thought2Text” by Mishra et al. in NAACL, which took an innovative multi-step approach to decode EEG signals evoked when subjects viewed images. I’m simplifying the following in favor of the big picture. First, they trained a neural network to convert raw EEG signals into an embedding space that aligns with those produced by CLIP, a model that understands images. We can think of an embedding as a very compressed representation of something that keeps only the most important information. Next, they trained a projector model (a neural network that maps between embedding spaces) to convert CLIP image embeddings into a format that an LLM can understand. Finally, they fine-tuned this projector to work directly with EEG embeddings. The final result is a pipeline able to read EEG signals and generate a text description of what a subject is seeing.
EEG lacks the spatial resolution of fMRI but has superior temporal resolution while also being a more accessible recording device. The finding that both forms of instrumentation show promise at neural decoding is encouraging, especially since variants of both devices could be combined to compensate for their respective limitations.
There are numerous other interesting projects like Brain Prompt-GPT, BrainLLM and MindLLM, which explore different ways to adapt sensor data as input to LLMs or develop neural decoding approaches that can work across subjects without individual calibration. While performance is far from perfect, this field is evolving quickly.
General technical commentary
A common strategy to this tech involves training a model to extract embeddings from brain signals and combining this with an LLM to convert those signal embeddings to text. The technical innovation is primarily in combining those steps in creative new ways to account for the complexity of brain signals and the shortcomings of the sensor modality, whether they be electrical signals measured from the scalp (EEG) or dynamic 3D blood flow patterns in the brain (fMRI).
It is an open question why LLMs are useful for decoding language from the brain. The scale of LLMs alone might provide a sufficiently rich embedding space to decode complex brain patterns, particularly if retrieved as subjective impressions or “gists” rather than as direct thought. Additionally, LLMs’ generative capabilities might help compensate for imperfect sensor data through semantic reconstruction i.e., “filling the gaps”. There is also speculation that language model architectures share common language processing strategies with the brain that support semantic alignment, e.g. via analogous hierarchical processing and word prediction mechanisms.
These LLM-based strategies are showing decent performance, too, often adapting established NLP metrics such as BERTScore and BLEU, which measure the semantic similarity or exact wording between decoded and reference text, respectively. Despite this progress, as a neuroscientist, I’m simply impressed that this area of research is possible at all. We’re still learning how language is processed in the brain, even at the fundamental level of brain regions and cortical pathways. It’s fascinating that neural activity can be abstracted into text using non-invasive techniques, especially since some of these studies capture widely dispersed neural patterns rather than targeting specific brain regions based on prior anatomical knowledge. Real-world applications aside, this research provides exciting new tools to study language processing in the brain and validate prevailing scientific theories.
This is not to say this field is without technical challenges. Much of this work has focused on evoked neural activity when subjects hear speech or view images. This provides valuable proof of concept that neural activity can be coherently decoded; however, there is likely greater clinical and commercial benefit to brain-computer interfaces that operate from imagined inner speech. Practical application may also be hindered by issues with decoding latency as well as sensor portability. Unlike EEG sensors, fMRIs are massive machines, and performance tradeoffs may emerge if wearable alternatives, such as functional near-infrared spectroscopy (fNIRS), are pursued. Additionally, both EEG and fMRI are highly sensitive to movement. For example, even subtle head movements like blinking create voltage deflections that cause EEG artifacts. Neural decoding models also need individual calibration, although recent developments, such as a 2025 follow-up study by Tang et al., may be overcoming this limitation. Finally and not least of all, the brain is plastic. It is uncertain what the neurophysiological implications are with these types of systems given the potential role of neuro-feedback, and how this might impact cognition and/or model performance with extended use.
Societal implications
While provocative, this research is not simply a parlor trick. It could lead to promising new medical devices for patients with impaired communication or mobility due to stroke or other neurological conditions. Its non-invasive nature makes it particularly advantageous for patients for whom invasive brain-computer interfaces, i.e. those requiring surgery and implants, are not recommended. While likely a more distant prospect, it’s easy to imagine broader consumer applications. And it might provoke reflections on our relationship with emerging technologies and what boundaries we may want to draw for ourselves.
While I believe that the catalytic role of GenAI in neural decoding has received underwhelming public reception, this topic has prompted new social policy. Neural information is intimate and at the core of our personhood. Its use might have unforeseen consequences, especially as this field evolves and while we have only a provisional understanding of the potential clinical and commercial reality. This gap has sparked efforts to define what are called “neurorights” that address topics like privacy and consent, agency and identity, augmentation and bias. Steps have begun to revise legislation as well. For example, Chile constitutionally protected neural rights in 2021, while California, Colorado, and Minnesota have enacted new neural data privacy laws. However, many open questions remain and shaping this research for responsible use will require both scientific literacy and strong public advocacy.
Why is nobody in tech talking about this?
The recent advances in non-invasive neural decoding deserve more attention given their potential clinical and societal impact, ethical implications and startling progress.
Having been on both sides of the academic/industry divide, one potential reason this has held a relatively low profile in tech may come down to how biological research differs from tech innovation.
Biotech development cycles are measured in years, not quarters. The clinical and commercial applications may be obvious in the long term, but they’re not immediate and are often high-risk.
There are also unique data constraints. Recent LLM advances have been driven by massive datasets scraped from the internet. By contrast, biological applications require actual humans to come into a lab and sit still for hours wearing EEG caps or lay motionless in expensive fMRI machines. Some public datasets exist but at a totally different scale.
There is also the constraint of niche subject expertise. This is complex data that requires a non-trivial understanding of brain anatomy, physiology, and neuro-imaging, a subspecialty among neuroscientists. Most ML engineers don’t have this background, and I suspect most brain imaging experts aren’t focused on applied LLMs.
However, big tech has been involved in this space for several years now. A recent example is Meta’s Brain2Qwerty. Given these firms’ massive capital and penchant for academic collaborations, these limitations may not withstand scrutiny.
I’m admittedly not very satisfied with any of these explanations. I think that the sheer novelty and technical ingenuity of this research should displace these practical considerations. Which leaves another possibility as to why attention is lagging: despite the scientific rigor, this topic is simply too outlandish and defies credulity. An AI agent that can book our flights we’ll accept. An AI sensor that can transcribe my thoughts? I’m gonna need some time to mull that over.
References
-
Tang J, LeBel A, Jain S, Huth AG. Semantic reconstruction of continuous language from non-invasive brain recordings. Nat Neurosci. 2023 May;26(5):858–66.
-
Ye Z, Ai Q, Liu Y, de Rijke M, Zhang M, Lioma C, et al. Generative language reconstruction from brain recordings. Commun Biol. 2025 Mar 1;8(1):346.
-
Caucheteux C, King JR. Brains and algorithms partially converge in natural language processing. Commun Biol. 2022 Feb 16;5(1):134.
-
Galke L, Ram Y, Raviv L. Deep neural networks and humans both benefit from compositional language structure. Nat Commun. 2024 Dec 30;15(1):10816.
-
Kumar S, Sumers TR, Yamakoshi T, Goldstein A, Hasson U, Norman KA, et al. Shared functional specialization in transformer-based language models and the human brain. Nat Commun. 2024 Jun 29;15(1):5523.
-
Saur D. Beyond ventral and dorsal streams: thalamo-cortical connections for subcortical language integration. Brain. 2024 Jun 1;147(6):1927–8.
-
Tang J, Huth AG. Semantic language decoding across participants and stimulus modalities. Curr Biol. 2025 Mar 10;35(5):1023-1032.e6.
-
Chile: Pioneering the protection of neurorights The UNESCO Courier [Internet]. [cited 2025 Jun 24].
-
Priola K, Baisley M, Soper M, Kipp C. Protect Privacy of Biological Data [Internet]. HB24-1058 2024.
-
SF 1110 as introduced - 93rd Legislature (2023 - 2024) [Internet]. 2023 [cited 2025 Jun 24].